[1]:
# fix python path if working locally
from utils import fix_pythonpath_if_working_locally
fix_pythonpath_if_working_locally()
[2]:
%load_ext autoreload
%autoreload 2
%matplotlib inline
[3]:
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from darts import TimeSeries
warnings.filterwarnings("ignore")
import logging
logging.disable(logging.CRITICAL)
静态协变量¶
静态协变量是时间序列的特征/常量,它们不会随时间变化。处理多个时间序列时,静态协变量可以帮助特定模型改进预测。Darts 的模型只会考虑嵌入在目标序列(我们想要预测未来值的序列)中的静态协变量,而不会考虑过去和/或未来协变量(外部数据)。
在本教程中,我们将学习
如何定义静态协变量(数值型和/或分类型)
如何将静态协变量添加到现有的 目标 序列
如何在创建 TimeSeries 时添加静态协变量
如何使用 TimeSeries.from_group_dataframe() 自动提取包含嵌入式静态协变量的时间序列
如何缩放/转换/编码嵌入在序列中的静态协变量
如何将静态协变量与 Darts 的模型一起使用
我们首先生成一个包含三个分量 ["comp1", "comp2", "comp3"] 的多元时间序列
[4]:
np.random.seed(0)
series = TimeSeries.from_times_and_values(
times=pd.date_range(start="2020-01-01", periods=10, freq="h"),
values=np.random.random((10, 3)),
columns=["comp1", "comp2", "comp3"],
)
series.plot()
1. 定义静态协变量¶
将静态协变量定义为一个 pd.DataFrame,其中列表示静态变量,行表示将添加这些协变量的单变量/多元 TimeSeries 的分量。
行数必须为 1 或等于
series的分量数量。将单行静态协变量 DataFrame 与多元(多分量)
series一起使用时,静态协变量将全局映射到所有分量。
[5]:
# arbitrary continuous and categorical static covariates (single row)
static_covs_single = pd.DataFrame(data={"cont": [0], "cat": ["a"]})
print(static_covs_single)
# multivariate static covariates (multiple components).
# note that the number of rows matches the number of components of `series`
static_covs_multi = pd.DataFrame(data={"cont": [0, 2, 1], "cat": ["a", "c", "b"]})
print(static_covs_multi)
cont cat
0 0 a
cont cat
0 0 a
1 2 c
2 1 b
2. 将静态协变量添加到现有时间序列¶
使用 with_static_covariates() 方法从现有 TimeSeries 创建一个带有添加静态协变量的新序列(参见此处的文档)
单行静态协变量与多元
series一起使用时会创建“global_components”,它们被映射到所有分量多行静态协变量与多元
series一起使用时将映射到series的分量名称(参见静态协变量索引/行名称)
[6]:
assert series.static_covariates is None
series_single = series.with_static_covariates(static_covs_single)
print("Single row static covarites with multivariate `series`")
print(series_single.static_covariates)
series_multi = series.with_static_covariates(static_covs_multi)
print("\nMulti row static covarites with multivariate `series`")
print(series_multi.static_covariates)
Single row static covarites with multivariate `series`
static_covariates cont cat
global_components 0.0 a
Multi row static covarites with multivariate `series`
static_covariates cont cat
component
comp1 0.0 a
comp2 2.0 c
comp3 1.0 b
3. 在时间序列构建时添加静态协变量¶
在创建时间序列时,也可以在大多数 TimeSeries.from_*() 方法中通过参数 static_covariates 直接添加静态协变量。
[7]:
# add arbitrary continuous and categorical static covariates
series = TimeSeries.from_values(
values=np.random.random((10, 3)),
columns=["comp1", "comp2", "comp3"],
static_covariates=static_covs_multi,
)
print(series.static_covariates)
static_covariates cont cat
component
comp1 0.0 a
comp2 2.0 c
comp3 1.0 b
将静态协变量用于多个时间序列¶
静态协变量仅在我们将其跨多个 TimeSeries 使用时才真正有用。按照惯例,所有序列的静态协变量布局(pd.DataFrame 列、索引)必须相同。
[8]:
first_series = series.with_static_covariates(
pd.DataFrame(data={"ID": ["SERIES1"], "var1": [0.5]})
)
second_series = series.with_static_covariates(
pd.DataFrame(data={"ID": ["SERIES2"], "var1": [0.75]})
)
print("Valid static covariates for multiple series")
print(first_series.static_covariates)
print(second_series.static_covariates)
series_multi = [first_series, second_series]
Valid static covariates for multiple series
static_covariates ID var1
global_components SERIES1 0.5
static_covariates ID var1
global_components SERIES2 0.75
4. 使用 from_group_dataframe() 从 DataFrame 按组提取时间序列列表¶
如果您的 DataFrame 包含多个垂直堆叠的时间序列,您可以使用 TimeSeries.from_group_dataframe()(参见此处的文档)将它们提取为 TimeSeries 实例列表。这需要一个或多个列作为 DataFrame 的分组依据(参数 group_cols)。group_cols 将自动作为静态协变量添加到各个序列中。其他列也可以通过参数 static_cols 用作静态协变量。
在下面的示例中,我们生成了一个 DataFrame,其中包含两个不同时间序列(日期重叠/重复)“SERIES1”和“SERIES2”的数据,并使用 from_group_dataframe() 提取 TimeSeries。
[9]:
# generate an DataFrame example
df = pd.DataFrame(
data={
"dates": [
"2020-01-01",
"2020-01-02",
"2020-01-03",
"2020-01-01",
"2020-01-02",
"2020-01-03",
],
"comp1": np.random.random((6,)),
"comp2": np.random.random((6,)),
"comp3": np.random.random((6,)),
"ID": ["SERIES1", "SERIES1", "SERIES1", "SERIES2", "SERIES2", "SERIES2"],
"var1": [0.5, 0.5, 0.5, 0.75, 0.75, 0.75],
}
)
print("Input DataFrame")
print(df)
series_multi = TimeSeries.from_group_dataframe(
df,
time_col="dates",
group_cols="ID", # individual time series are extracted by grouping `df` by `group_cols`
static_cols=[
"var1"
], # also extract these additional columns as static covariates (without grouping)
value_cols=[
"comp1",
"comp2",
"comp3",
], # optionally, specify the time varying columns
)
print(f"\n{len(series_multi)} series were extracted from the input DataFrame")
for i, ts in enumerate(series_multi):
print(f"Static covariates of series {i}")
print(ts.static_covariates)
ts["comp1"].plot(label=f"comp1_series_{i}")
Input DataFrame
dates comp1 comp2 comp3 ID var1
0 2020-01-01 0.158970 0.820993 0.976761 SERIES1 0.50
1 2020-01-02 0.110375 0.097101 0.604846 SERIES1 0.50
2 2020-01-03 0.656330 0.837945 0.739264 SERIES1 0.50
3 2020-01-01 0.138183 0.096098 0.039188 SERIES2 0.75
4 2020-01-02 0.196582 0.976459 0.282807 SERIES2 0.75
5 2020-01-03 0.368725 0.468651 0.120197 SERIES2 0.75
2 series were extracted from the input DataFrame
Static covariates of series 0
static_covariates ID var1
global_components SERIES1 0.5
Static covariates of series 1
static_covariates ID var1
global_components SERIES2 0.75
5. 缩放/编码/转换静态协变量数据¶
可能需要对数值型静态协变量进行缩放,或对分类静态协变量进行编码,因为并非所有模型都能处理非数值型静态协变量。
使用 StaticCovariatesTransformer(参见此处的文档)来缩放/转换静态协变量。默认情况下,它使用 MinMaxScaler 缩放数值数据,并使用 OrdinalEncoder 编码分类数据。数值型和分类型转换器都将在传递给 StaticCovariatesTransformer.fit() 的所有时间序列的静态协变量数据上进行全局拟合。
[10]:
from darts.dataprocessing.transformers import StaticCovariatesTransformer
transformer = StaticCovariatesTransformer()
series_transformed = transformer.fit_transform(series_multi)
for i, (ts, ts_scaled) in enumerate(zip(series_multi, series_transformed)):
print(f"Original series {i}")
print(ts.static_covariates)
print(f"Transformed series {i}")
print(ts_scaled.static_covariates)
print("")
Original series 0
static_covariates ID var1
global_components SERIES1 0.5
Transformed series 0
static_covariates ID var1
global_components 0.0 0.0
Original series 1
static_covariates ID var1
global_components SERIES2 0.75
Transformed series 1
static_covariates ID var1
global_components 1.0 1.0
6. 使用 TFTModel 和静态协变量的预测示例¶
现在我们来看看将静态协变量添加到预测问题中是否可以提高预测准确性。我们将使用支持数值型和分类型静态协变量的 TFTModel。
[11]:
import numpy as np
import pandas as pd
from pytorch_lightning.callbacks import TQDMProgressBar
from darts import TimeSeries
from darts.dataprocessing.transformers import StaticCovariatesTransformer
from darts.metrics import rmse
from darts.models import TFTModel
from darts.utils import timeseries_generation as tg
6.1 实验设置¶
对于我们的实验,我们生成两个时间序列:一个完全正弦波序列(标签 = smooth)和一个每隔一个周期带有一些不规则性(标签 = irregular,参见周期 2 和 4 的斜坡)的正弦波序列。
[12]:
period = 20
sine_series = tg.sine_timeseries(
length=4 * period, value_frequency=1 / period, column_name="smooth", freq="h"
)
sine_vals = sine_series.values()
linear_vals = np.expand_dims(np.linspace(1, -1, num=19), -1)
sine_vals[21:40] = linear_vals
sine_vals[61:80] = linear_vals
irregular_series = TimeSeries.from_times_and_values(
values=sine_vals, times=sine_series.time_index, columns=["irregular"]
)
sine_series.plot()
irregular_series.plot()
我们将使用三种不同的设置进行训练和评估
不使用静态协变量进行拟合/预测
使用二进制(数值型)静态协变量进行拟合/预测
使用分类静态协变量进行拟合/预测
对于每种设置,我们都会在两个序列上训练模型,然后仅使用第三个周期(两个序列都是正弦波)来预测第四个周期(“smooth”是正弦波,“irregular”是斜坡)。
我们希望不使用静态协变量的模型性能比其他模型差。不使用静态协变量的模型应该无法识别在 predict() 中使用的底层序列是 smooth 还是 irregular,因为它只将正弦波曲线作为输入(第三个周期)。这应该导致预测结果介于 smooth 和 irregular 序列之间(通过在训练期间最小化全局损失来学习)。
现在,静态协变量正可以在这里发挥作用。例如,我们可以通过静态协变量将关于曲线类型的数据嵌入到 目标 序列中。有了这些信息,我们期望模型能够生成改进的预测。
首先,我们创建一些辅助函数,将相同的实验条件应用于所有模型。
[13]:
def test_case(model, train_series, predict_series):
"""helper function which performs model training, prediction and plotting"""
model.fit(train_series)
preds = model.predict(n=int(period / 2), num_samples=250, series=predict_series)
for ts, ps in zip(train_series, preds):
ts.plot()
ps.plot()
plt.show()
return preds
def get_model_params():
"""helper function that generates model parameters with a new Progress Bar object"""
return {
"input_chunk_length": int(period / 2),
"output_chunk_length": int(period / 2),
"add_encoders": {
"datetime_attribute": {"future": ["hour"]}
}, # TFTModel requires future input, with this we won't have to supply any future_covariates
"random_state": 42,
"n_epochs": 150,
"pl_trainer_kwargs": {
"callbacks": [TQDMProgressBar(refresh_rate=4)],
},
}
6.2 不使用静态协变量进行预测¶
让我们训练第一个不包含任何静态协变量的模型
[14]:
train_series = [sine_series, irregular_series]
for series in train_series:
assert not series.has_static_covariates
model = TFTModel(**get_model_params())
preds = test_case(
model,
train_series,
predict_series=[series[:60] for series in train_series],
)
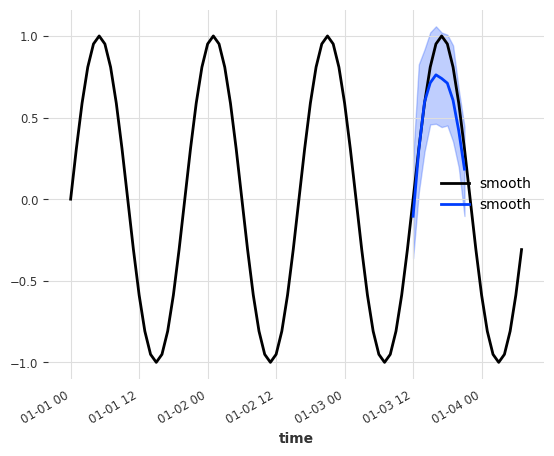
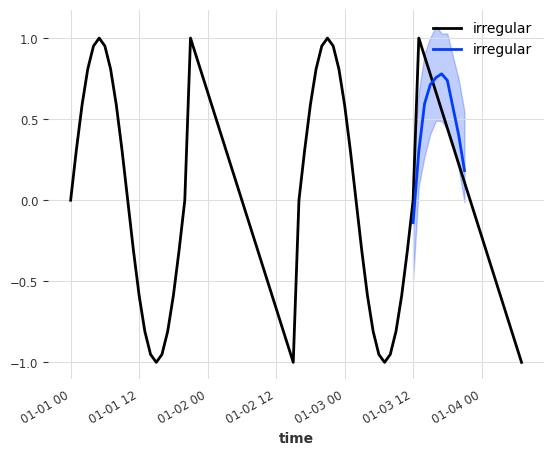
从图中可以看出,预测从第三个周期(约 2022 年 1 月 3 日 - 12:00)之后开始。预测输入是最后 input_chunk_length=10 个值 - 这对于两个序列(正弦波)是相同的。
正如预期的那样,模型无法确定底层预测序列的类型(smooth 或 irregular),并且为两者生成了类似正弦波的预测。
6.3 使用 0/1 二进制静态协变量(数值型)进行预测¶
现在我们重复这个实验,但这次我们将曲线类型的信息作为名为 "curve_type" 的二进制(数值型)静态协变量添加。
[15]:
sine_series_st_bin = sine_series.with_static_covariates(
pd.DataFrame(data={"curve_type": [1]})
)
irregular_series_st_bin = irregular_series.with_static_covariates(
pd.DataFrame(data={"curve_type": [0]})
)
train_series = [sine_series_st_bin, irregular_series_st_bin]
for series in train_series:
print(series.static_covariates)
model = TFTModel(**get_model_params())
preds_st_bin = test_case(
model,
train_series,
predict_series=[series[:60] for series in train_series],
)
static_covariates curve_type
component
smooth 1.0
static_covariates curve_type
component
irregular 0.0
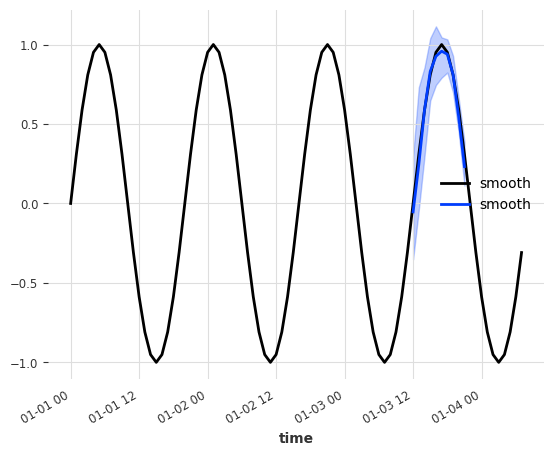
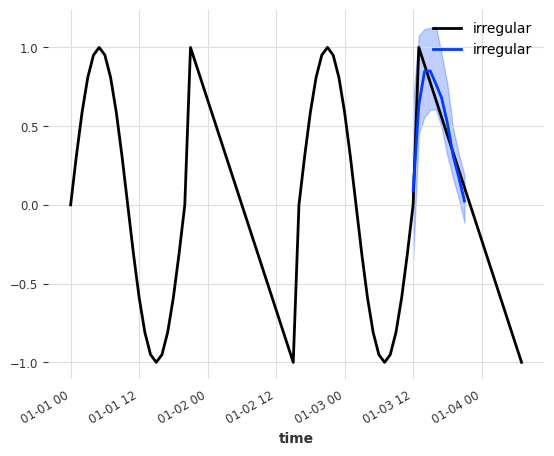
这看起来好多了!模型能够从二进制静态协变量特征中识别曲线类型/类别。
6.4 使用分类静态协变量进行预测¶
上一个实验已经显示了有希望的结果。那么为什么不只对分类数据使用二进制特征呢?虽然这对我们的两个时间序列可能效果很好,但如果我们有更多的曲线类型,我们就需要将特征进行独热编码(one hot encode),为每个类别转换为一个二进制变量。如果类别很多,这会导致大量特征/预测变量和多重共线性,从而降低模型的预测准确性。
作为最后一个实验,让我们使用曲线类型作为分类特征。TFTModel 为分类特征学习嵌入。Darts 的 TorchForecastingModels(例如 TFTModel)仅支持数值数据。在训练之前,我们需要使用 StaticCovariatesTransformer 将 "curve_type" 转换为整数值特征(参见第 5 节)。
[16]:
sine_series_st_cat = sine_series.with_static_covariates(
pd.DataFrame(data={"curve_type": ["smooth"]})
)
irregular_series_st_cat = irregular_series.with_static_covariates(
pd.DataFrame(data={"curve_type": ["non_smooth"]})
)
train_series = [sine_series_st_cat, irregular_series_st_cat]
print("Static covariates before encoding:")
print(train_series[0].static_covariates)
# use StaticCovariatesTransformer to encode categorical static covariates into numeric data
scaler = StaticCovariatesTransformer()
train_series = scaler.fit_transform(train_series)
print("\nStatic covariates after encoding:")
print(train_series[0].static_covariates)
Static covariates before encoding:
static_covariates curve_type
component
smooth smooth
Static covariates after encoding:
static_covariates curve_type
component
smooth 1.0
现在,我们所需要做的就是告诉 TFTModel,"curve_type" 是一个需要嵌入的分类变量。我们可以使用模型参数 categorical_embedding_sizes 来做到这一点,它是一个字典,格式为:{特征名称: (类别数量, 嵌入大小)}
[17]:
n_categories = 2 # "smooth" and "non_smooth"
embedding_size = 2 # embed the categorical variable into a numeric vector of size 2
categorical_embedding_sizes = {"curve_type": (n_categories, embedding_size)}
model = TFTModel(
categorical_embedding_sizes=categorical_embedding_sizes, **get_model_params()
)
preds_st_cat = test_case(
model,
train_series,
predict_series=[series[:60] for series in train_series],
)
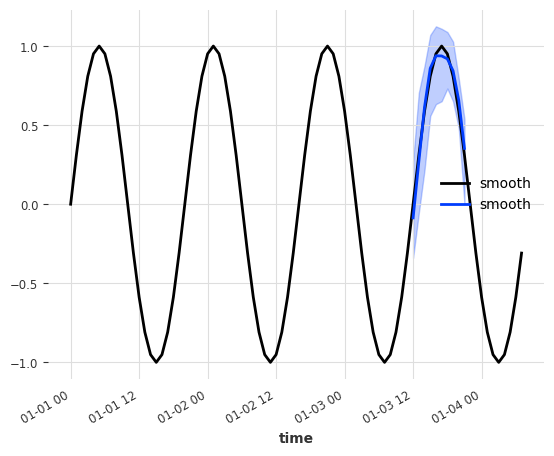
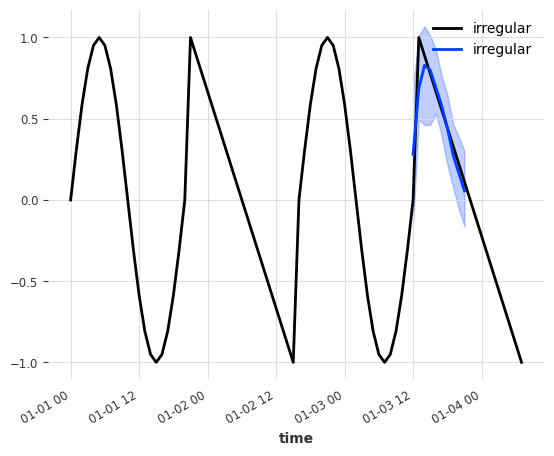
很好,这似乎也奏效了!作为最后一步,让我们看看模型相互比较的性能如何。
[18]:
for series, ps_no_st, ps_st_bin, ps_st_cat in zip(
train_series, preds, preds_st_bin, preds_st_cat
):
series[-40:].plot(label="target")
ps_no_st.quantile(0.5).plot(label="no static covs")
ps_st_bin.quantile(0.5).plot(label="binary static covs")
ps_st_cat.quantile(0.5).plot(label="categorical static covs")
plt.show()
print("Metric")
print(
pd.DataFrame(
{
name: [rmse(series, ps)]
for name, ps in zip(
["no st", "bin st", "cat st"], [ps_no_st, ps_st_bin, ps_st_cat]
)
},
index=["RMSE"],
)
)
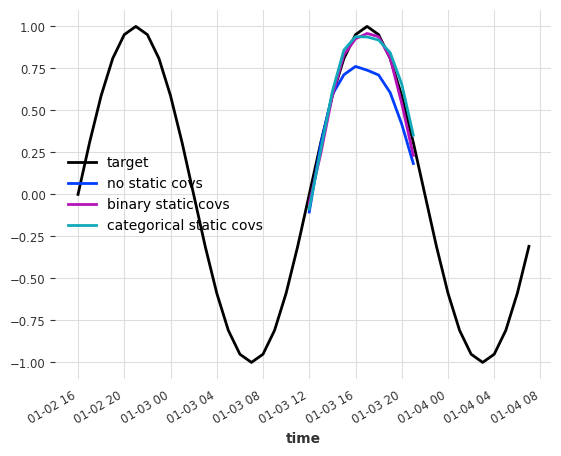
Metric
no st bin st cat st
RMSE 0.16352 0.042527 0.050242
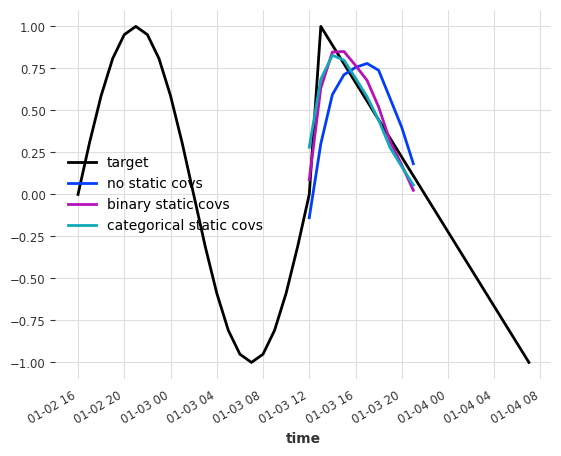
Metric
no st bin st cat st
RMSE 0.289051 0.138122 0.138631
这些结果非常出色!与基线相比,使用静态协变量的两种方法都使两个序列的 RMSE 降低了一半以上!
请注意,我们只使用了一个静态协变量特征,但您可以根据需要使用任意数量的特征,包括混合数据类型(数值型和分类型)。