回归模型¶
以下是 Darts 中回归模型的深入演示 - 从基本到高级功能,包括:
Darts 的回归模型
滞后和滞后数据提取
协变量使用
参数
output_chunk_length与multi_models的关系一次性预测和自回归预测
多输出支持
概率预测
可解释性
以及更多
[1]:
# fix python path if working locally
from utils import fix_pythonpath_if_working_locally
fix_pythonpath_if_working_locally()
# activate javascript
from shap import initjs
initjs()
Using `tqdm.autonotebook.tqdm` in notebook mode. Use `tqdm.tqdm` instead to force console mode (e.g. in jupyter console)

[2]:
%load_ext autoreload
%autoreload 2
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import BayesianRidge
from darts.datasets import ElectricityConsumptionZurichDataset
from darts.explainability import ShapExplainer
from darts.metrics import mape
from darts.models import (
CatBoostModel,
LightGBMModel,
LinearRegressionModel,
RegressionModel,
XGBModel,
)
输入数据集¶
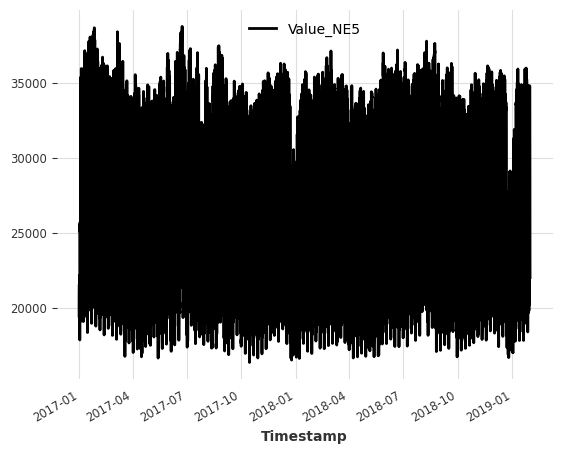
在本 notebook 中,我们使用来自瑞士苏黎世家庭的电力消耗数据集。
数据集的频率为刻钟(15 分钟时间间隔),但为了简单起见,我们将其重采样为小时频率。
目标序列(我们希望预测的序列): - Value_NE5:网格级别 5 家庭的电力消耗量(以千瓦时为单位)。
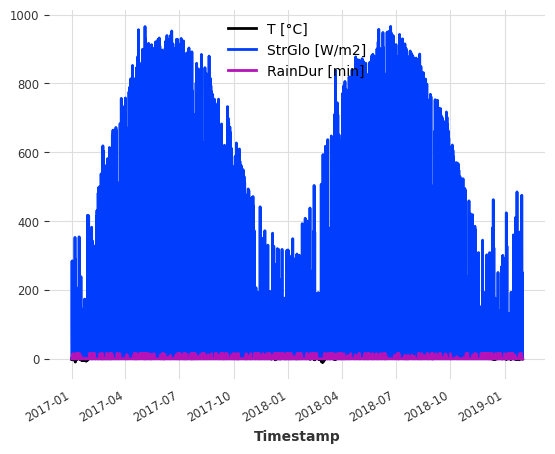
协变量(有助于改进预测的外部数据):数据集还包含天气测量数据,我们可以将其用作协变量。为简单起见,我们使用: - T [°C]:测量的温度 - StrGlo [W/m2]:测量的太阳辐照度 - RainDur [min]:测量的降雨持续时间
[3]:
ts_energy = ElectricityConsumptionZurichDataset().load()
# extract values recorded between 2017 and 2019
start_date = pd.Timestamp("2017-01-01")
end_date = pd.Timestamp("2019-01-31")
ts_energy = ts_energy[start_date:end_date]
# resample to hourly frequency
ts_energy = ts_energy.resample(freq="H")
# extract temperature, solar irradiation and rain duration
ts_weather = ts_energy[["T [°C]", "StrGlo [W/m2]", "RainDur [min]"]]
# extract households energy consumption
ts_energy = ts_energy["Value_NE5"]
# create train and validation splits
validation_cutoff = pd.Timestamp("2018-10-31")
ts_energy_train, ts_energy_val = ts_energy.split_after(validation_cutoff)
ts_energy.plot()
plt.show()
ts_weather.plot()
plt.show()
Darts 回归模型¶
回归是数据科学和机器学习中用于模拟因变量(目标 y)与一个或多个自变量(特征 X)之间关系的统计方法。
为方便起见,Darts 核心包附带了几个回归模型: - LinearRegressionModel 和 RandomForest:完全集成的 sklearn 模型 - RegressionModel:将 Darts Model API 包装到任何类 sklearn 模型上 - XGBModel:XGBoost 的 XGBRegressor 包装器
除此之外,我们还为一些最先进的回归模型提供统一的 API,这些模型可以按照我们的安装指南进行安装
LightGBMModel:LightGBM 的LightGBMRegressor包装器CatBoostModel:CatBoost 的CatBoostRegressor包装器。
在 Darts 中,通过将时间序列转换为两个表格数组,预测问题被转化为回归问题: - X:形状为(样本/观测数,特征数)的特征或输入数组 - 特征数由(特征特定的)目标、过去和未来协变量滞后的总数给出。 - y:形状为(样本/观测数,目标数)的目标或标签数组 - 目标数由模型参数 output_chunk_length 和 multi_models 给出(我们稍后会解释这一点)。
目标和协变量滞后¶
滞后特征是与某个参考点相比,特征在之前或未来时间步的值。
在 Darts 中,滞后的值指定了特征值相对于每个观测/样本(X 中的一行)的第一个预测目标时间步 y_t0 的位置。
lag == 0:第一个预测时间步t0的位置,例如y_t0的位置lag < 0:第一个预测时间步t-1,t-2, … 的过去所有位置lag > 0:第一个预测时间步t+1,t+2, … 的未来所有位置
滞后的选择对于获得良好的预测精度至关重要。我们希望模型接收相关信息,以捕获目标序列的时间属性/依赖关系(模式、季节性、趋势等)。它还对模型性能/复杂性产生相当大的影响,因为每个额外的滞后都会向 X 添加一个新特征。
在创建模型时,我们可以分别为目标序列和协变量序列设置滞后。
lags:目标序列(我们希望预测的序列)的滞后lags_past_covariates:可选的,过去协变量序列(外部过去观测特征,有助于改进预测)的滞后lags_future_covariates:可选的,未来协变量序列(外部未来已知特征,有助于改进预测)的滞后
有多种方法可以定义您的滞后,例如 (int, List[int], Tuple[int, int], ...)。您可以在RegressionModel 文档中找到更多信息。
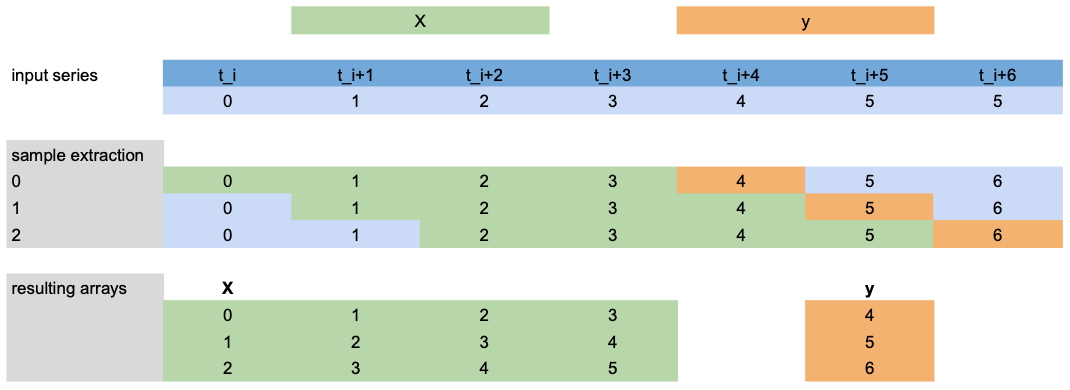
滞后数据提取¶
现在,让我们看看如何使用下面的场景提取 X 和 y 进行训练
lags=[-4,-3,-2,-1]:使用第一个预测时间步(橙色)之前的最后 4 个目标值(绿色)作为X特征。output_chunk_length=1:预测下一个(1)时间步(橙色)的目标值y。我们有一个包含 7 个时间步
t_i, ..., t_i+6(蓝色)的目标序列。
注意:此示例仅显示目标 ``lags`` 提取,但同样的逻辑也适用于 ``lags_past/future_covariates``。
示例¶
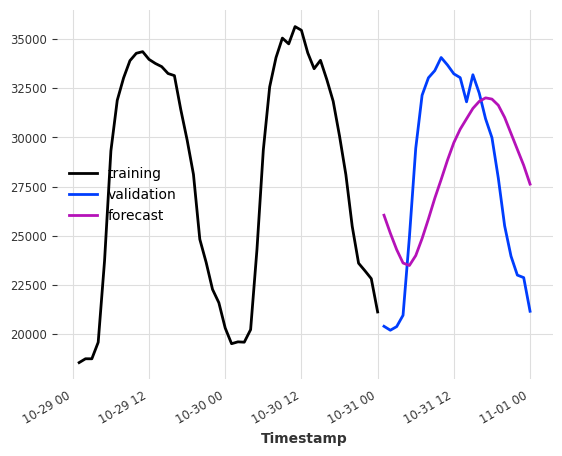
让我们尝试将此应用于我们的电力数据集。假设我们想预测训练集结束后未来几个小时的消耗量。
作为输入特征,我们使用一天和两天前同一小时的消耗量 -> lags=[-24, -48]。
[4]:
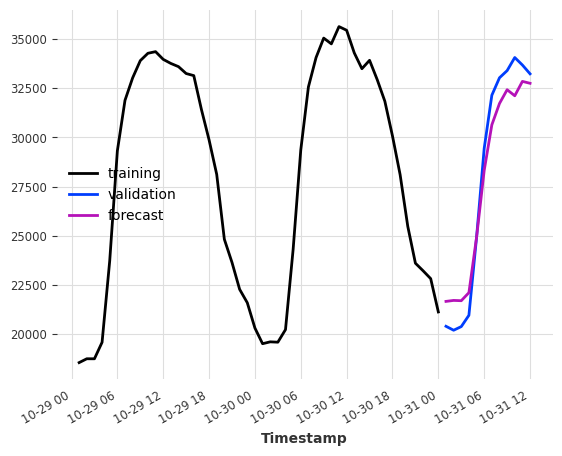
model = LinearRegressionModel(lags=[-24, -48])
model.fit(ts_energy_train)
pred = model.predict(12)
ts_energy_train[-48:].plot(label="training")
ts_energy_val[:12].plot(label="validation")
pred.plot(label="forecast")
[4]:
<Axes: xlabel='Timestamp'>
基于协变量的预测¶
要在目标序列历史数据旁边使用外部数据,我们需要指定过去和/或未来协变量滞后,然后将 past_covariates 和/或 future_covariates 传递给 fit() 和 predict()。
假设我们没有天气测量数据,而是有天气预报。那么我们可以将它们用作 future_covariates。我们在这里这样做仅为演示目的!
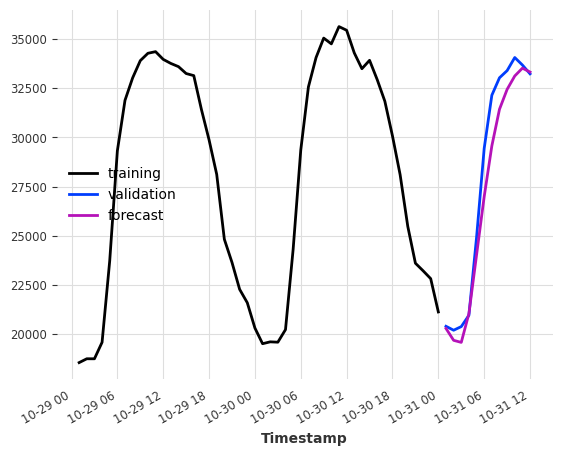
下面是一个示例,它使用目标序列(电力消耗)的最后 24 小时(24)以及我们的天气“预报”在预测时间步([0])的值。
[5]:
model = LinearRegressionModel(lags=24, lags_future_covariates=[0])
model.fit(ts_energy_train, future_covariates=ts_weather)
pred = model.predict(12)
ts_energy_train[-48:].plot(label="training")
ts_energy_val[:12].plot(label="validation")
pred.plot(label="forecast")
[5]:
<Axes: xlabel='Timestamp'>
仅使用协变量¶
有时,我们也可能对仅依赖于协变量值的预测模型感兴趣。
要做到这一点,请指定 lags_past_covariates 或 lags_future_covariates 中的至少一个,并将 lags=None。Darts 回归模型以监督方式训练,因此我们仍然需要提供目标序列进行训练。
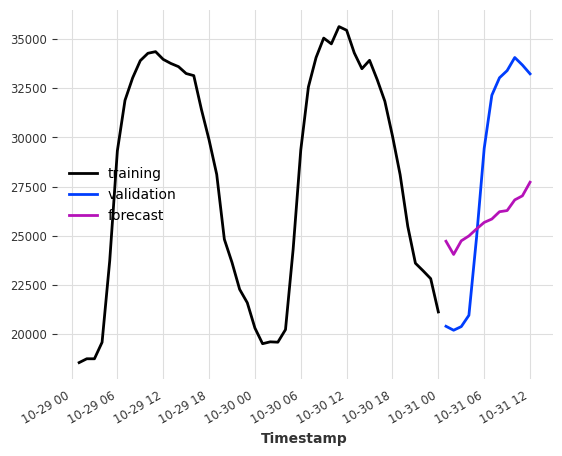
仅使用天气“预报”作为输入,我们能多好地预测电力消耗?
滞后元组 (24, 1) 表示(过去滞后数,未来滞后数)。
[6]:
model = LinearRegressionModel(lags=None, lags_future_covariates=(24, 1))
model.fit(series=ts_energy_train, future_covariates=ts_weather)
pred = model.predict(12)
ts_energy_train[-48:].plot(label="training")
ts_energy_val[:12].plot(label="validation")
pred.plot(label="forecast")
[6]:
<Axes: xlabel='Timestamp'>
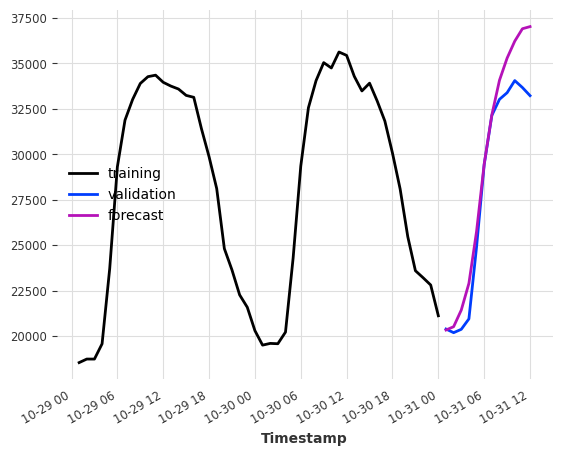
如果我们添加一些日历信息呢?我们可以使用 add_encoders 让模型免费生成日历属性编码。
[7]:
model = LinearRegressionModel(
lags=None,
lags_future_covariates=(24, 1),
add_encoders={
"cyclic": {"future": ["minute", "hour", "dayofweek", "month"]},
"tz": "CET",
},
)
model.fit(series=ts_energy_train, future_covariates=ts_weather)
pred = model.predict(12)
ts_energy_train[-48:].plot(label="training")
ts_energy_val[:12].plot(label="validation")
pred.plot(label="forecast")
plt.show()
组件特定滞后¶
如果目标或任何协变量是多变量的(具有多个组件/列),我们可以为每个组件使用专门的滞后。只需将一个字典传递给 lags* 参数,其中键是组件名称,值是滞后。
在下面的示例中,我们将默认滞后设置为 (24,1)(用于协变量组件 'T [°C]' 和 'StrGlo [W/ms]'),并为特征 'RainDur [min]' 指定一个专门的滞后 [0]。
[8]:
model = LinearRegressionModel(
lags=None, lags_future_covariates={"default_lags": (24, 1), "RainDur [min]": [0]}
)
model.fit(series=ts_energy_train, future_covariates=ts_weather)
pred = model.predict(12)
ts_energy_train[-48:].plot(label="training data")
ts_energy_val[:12].plot(label="validation data")
pred.plot(label="forecast")
[8]:
<Axes: xlabel='Timestamp'>
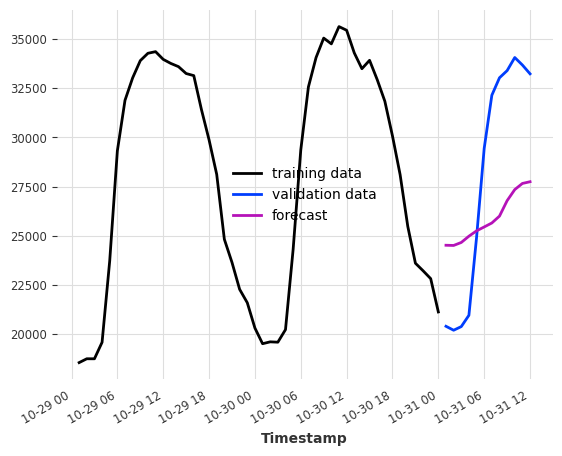
模型的输出块长度¶
这个关键参数设置了内部回归模型可以一次性预测的时间步数。
它与 predict() 中的预测范围 n 不同,n 是期望的生成的预测点数,其实现方式可以是: - 单次预测(如果 n <= output_chunk_length),或 - 自回归预测,将自身的预测(以及协变量的未来值)作为输入进行额外的预测(否则)
例如,如果我们希望模型根据前一天的消耗量预测未来 24 小时的电力消耗,设置 output_chunk_length=24 可以确保模型不会消耗其自身的预测值或协变量的未来值来预测整天的数据。
[9]:
model_auto_regression = LinearRegressionModel(lags=24, output_chunk_length=1)
model_single_shot = LinearRegressionModel(lags=24, output_chunk_length=24)
model_auto_regression.fit(ts_energy_train)
model_single_shot.fit(ts_energy_train)
pred_auto_regression = model_auto_regression.predict(24)
pred_single_shot = model_single_shot.predict(24)
ts_energy_train[-48:].plot(label="training data")
ts_energy_val[:24].plot(label="validation data")
pred_auto_regression.plot(label="forecast (auto-regression)")
pred_single_shot.plot(label="forecast (single-shot)")
[9]:
<Axes: xlabel='Timestamp'>
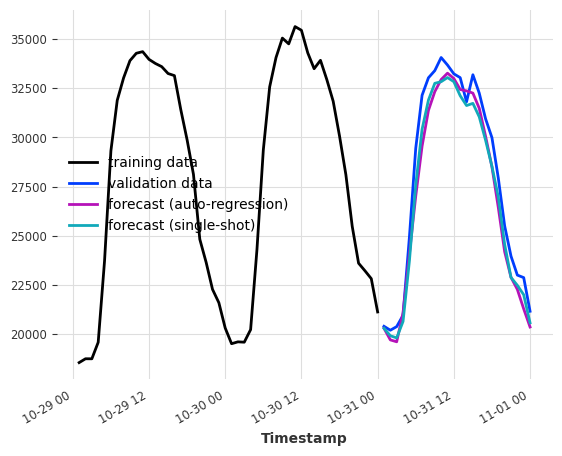
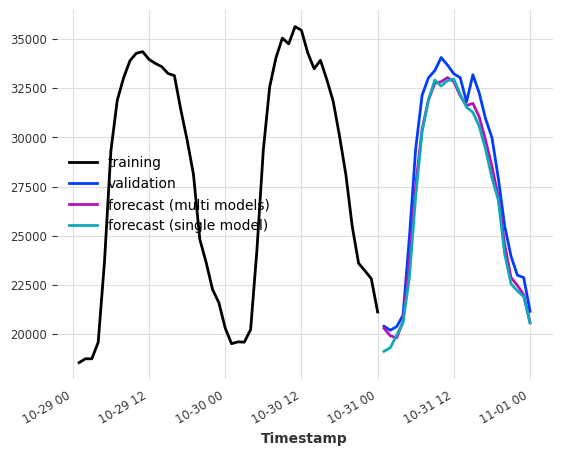
多模型预测¶
当 output_chunk_length>1 时,可以通过修改 multi_models 参数进一步参数化模型行为。
multi_models=True 是 Darts 中的默认行为,如上所示。我们创建模型的 output_chunk_length 个副本,并训练每个副本以预测 output_chunk_length 个时间步中的一个(使用相同的输入)。这种方法计算和内存密集度更高,但往往会产生更好的结果。
单模型预测¶
当 multi_model=False 时,我们使用单个模型并训练它仅预测 output_chunk_length 中的最后一个点。这降低了模型复杂性,因为只需要训练和存储一组系数。
通过在表格化过程中移动滞后,我们仍然能够预测从 1 到 output_chunk_length 的所有点。这意味着每个预测值都使用一组新的输入值。由于这种移动,训练序列的最小长度要求也会增加。
[10]:
multi_models = LinearRegressionModel(lags=24, output_chunk_length=24, multi_models=True)
single_model = LinearRegressionModel(
lags=24, output_chunk_length=24, multi_models=False
)
multi_models.fit(ts_energy_train)
single_model.fit(ts_energy_train)
pred_multi_models = multi_models.predict(24)
pred_single_model = single_model.predict(24)
ts_energy_train[-48:].plot(label="training")
ts_energy_val[:24].plot(label="validation")
pred_multi_models.plot(label="forecast (multi models)")
pred_single_model.plot(label="forecast (single model)")
[10]:
<Axes: xlabel='Timestamp'>
可视化¶
为了可视化内部发生的情况,让我们稍微简化模型,并展示不同参数的过程。
模型设置:LinearRegressionModel(lags=[-4, -3, -2, -1], output_chunk_length=2, multi_models=True)。
调用 predict(n=4) 时,输入序列的处理过程如下
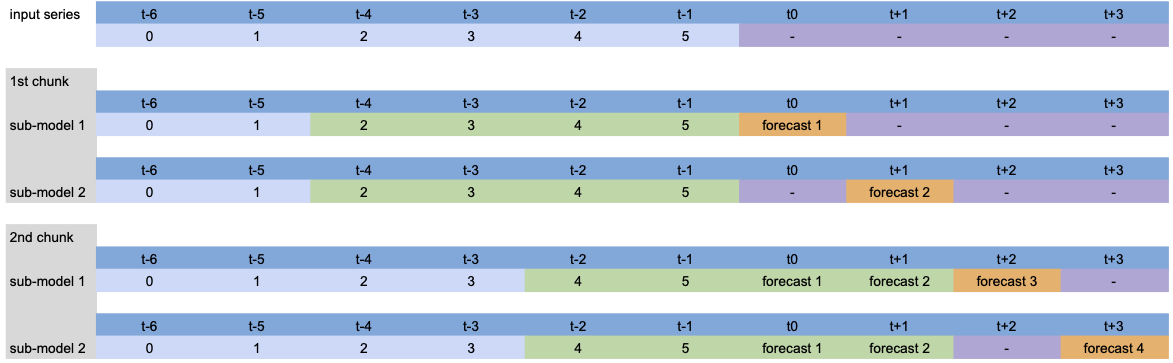
由于 n>output_chunk_length,模型必须使用自回归,预测周期由两个大小为 output_chunk_length 的块组成。每个输出块没有滞后移动,因为 multi_models=True。
模型设置:LinearRegressionModel(lags=[-4, -3, -2, -1], output_chunk_length=2, multi_models=False)。
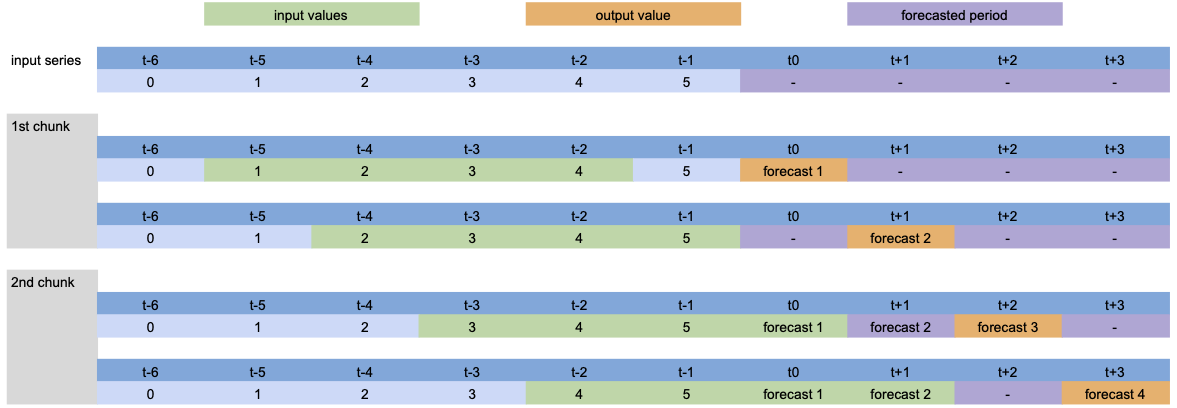
除了自回归预测外,我们可以看到每个预测时间步的滞后移动,因为 multi_models=False。
在模型训练的表格化过程中也会发生同样的过程:每个绿色块与一个橙色值配对,构成训练数据集。
概率预测¶
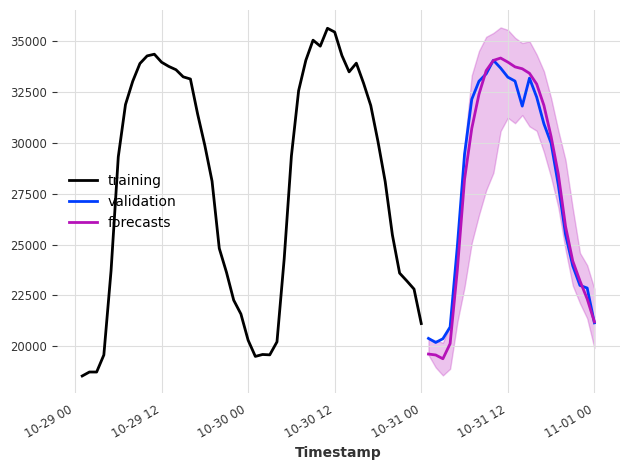
要使模型具有概率性,在创建 RegressionModel 时将参数 likelihood 设置为 quantile 或 poisson。在预测时,概率模型可以: - 当 num_samples > 1 时,使用蒙特卡罗采样根据拟合的分布参数生成样本 - 当 predict_likelihood_parameters=True 时,返回拟合的分布参数
请注意,当使用 quantile 回归器时,每个分位数将由不同的模型拟合。
每次调用 predict() 并设置 num_samples > 1 时,概率模型将生成不同的预测结果。为了获得可复现的结果,请在创建模型时设置随机种子,并以完全相同的顺序调用方法。
[11]:
model = XGBModel(
lags=24, output_chunk_length=1, likelihood="quantile", quantiles=[0.05, 0.5, 0.95]
)
model.fit(ts_energy_train)
pred_samples = model.predict(n=24, num_samples=200)
pred_params = model.predict(n=1, num_samples=1, predict_likelihood_parameters=True)
for val, comp in zip(pred_params.values()[0], pred_params.components):
print(f"{comp} : {round(val, 3)}")
ts_energy_train[-48:].plot(label="training")
ts_energy_val[:24].plot(label="validation")
pred_samples.plot(label="forecasts")
plt.tight_layout()
Value_NE5_q0.05 : 19580.123046875
Value_NE5_q0.50 : 19623.302734375
Value_NE5_q0.95 : 20418.7421875
MultiOutputRegressor 包装器¶
一些回归模型原生支持多输出。这对于拟合和预测以下情况是必需的: - 多个输出/多个目标步长(当 output_chunk_length>1 且 multi_models=True 时) - 使用分位数回归的概率模型 - 多变量序列
对于不支持原生多输出的模型,Darts 会在其外部包装 sklearn 的 MultiOutputRegressor 来处理内部逻辑。
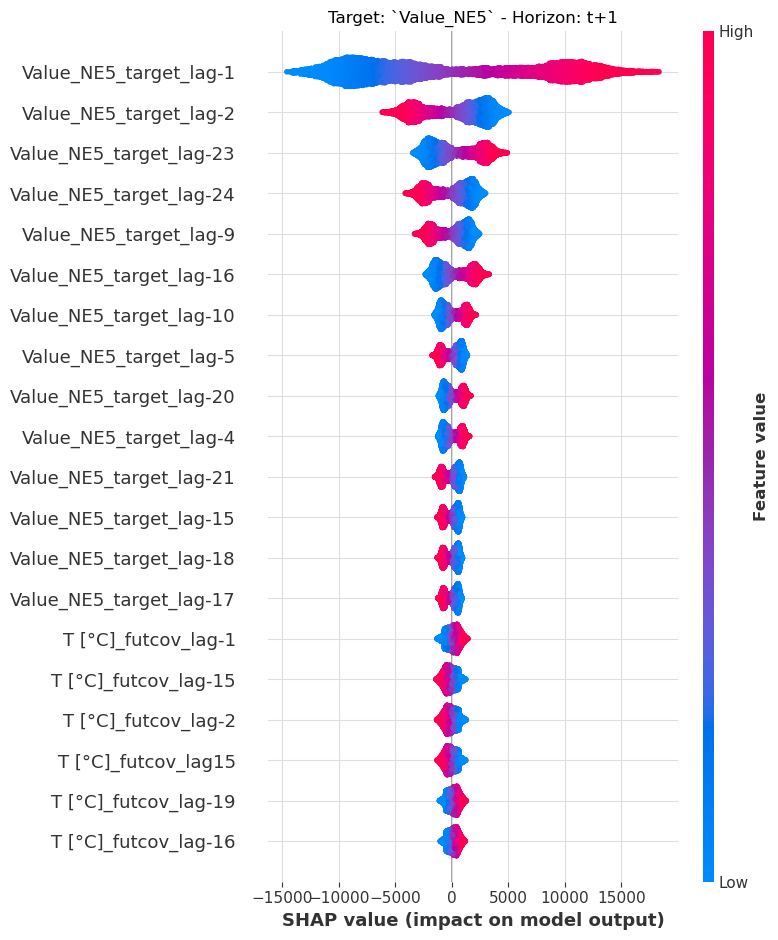
可解释性¶
我们使用 Darts 的 ShapExplainer 为回归模型提供可解释性。该解释器使用基于博弈论的库 shap,以便深入了解我们的预测范围内特征重要性随时间的变化。
[12]:
model = LinearRegressionModel(lags=24, lags_future_covariates=(24, 24))
model.fit(ts_energy_train, future_covariates=ts_weather)
shap_explainer = ShapExplainer(model=model)
shap_values = shap_explainer.summary_plot()
No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored
[13]:
# extracting the end of each series to reduce computation time
foreground_target = ts_energy_train[-24 * 2 :]
foreground_future_cov = ts_weather[foreground_target.start_time() :]
shap_explainer.force_plot_from_ts(
foreground_series=foreground_target,
foreground_future_covariates=foreground_future_cov,
)
# the plot cannot be rendered on GitHub or the Documentation page. Run it locally to see it.
[13]:
您是否在此 notebook 中运行了 `initjs()`?如果此 notebook 来自其他用户,您还必须信任此 notebook(文件 -> 信任 notebook)。如果您在 GitHub 上查看此 notebook,Javascript 已出于安全原因被移除。如果您正在使用 JupyterLab,此错误是因为尚未编写 JupyterLab 扩展。
结论¶
通过将数据表格化并统一跨库的 API,Darts 弥合了传统回归问题与时间序列预测之间的差距。
RegressionModel 及其子类提供了广泛的功能,只需几行代码即可构建强大的模型。
附录¶
RegressionModel¶
RegressionModel 将 Darts API 包装在任何 sklearn 回归模型上。通过这种方式,我们可以像使用任何其他 Darts 预测模型一样使用该模型。
作为一个例子,在示例数据集上拟合 Bayesian ridge 回归只需要几行代码
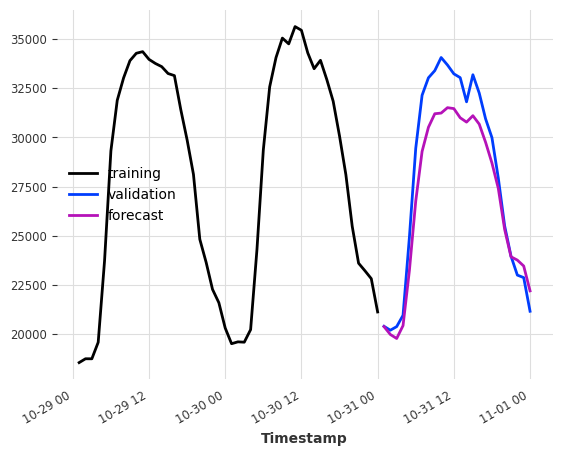
[14]:
model = RegressionModel(
lags=24,
lags_future_covariates=(48, 24),
model=BayesianRidge(),
output_chunk_length=24,
)
model.fit(ts_energy_train, future_covariates=ts_weather)
pred = model.predict(n=24)
ts_energy_train[-48:].plot(label="training")
ts_energy_val[:24].plot(label="validation")
pred.plot(label="forecast")
[14]:
<Axes: xlabel='Timestamp'>
底层模型方法仍然可访问,通过结合 BasesianRidge.coef_ 属性和 RegressionModel.lagged_feature_names 属性,可以轻松解释回归模型的系数
[15]:
# extract the coefficients of the first timestemp estimator
coef_values = model.model.estimators_[0].coef_
# get the lagged features name
coef_names = model.lagged_feature_names
# combine them in a dict
coefficients = {name: val for name, val in zip(coef_names, coef_values)}
# see the coefficient of the target value at last timestep before the forecasted period
{c_name: c_val for idx, (c_name, c_val) in enumerate(coefficients.items()) if idx < 5}
[15]:
{'Value_NE5_target_lag-24': -0.3195560563281926,
'Value_NE5_target_lag-23': 0.37621876784175745,
'Value_NE5_target_lag-22': 0.005325414282057739,
'Value_NE5_target_lag-21': -0.11885377506043901,
'Value_NE5_target_lag-20': 0.12892167797527437}
RegressionModel 类的一个限制是它不直接提供概率预测,但可以通过创建一个继承自 RegressionModel 和 _LikelihoodMixin 并实现缺失方法的新类来实现(LinearRegressionModel 类可以用作模板)。
自定义模型¶
您甚至可以实现自己的模型,只要它能处理表格数据并提供 fit() 和 predict() 方法即可
[16]:
class CustomRegressionModel:
def __init__(self, weights: np.ndarray):
"""Barebone weighted average"""
self.weights = weights
self.norm_coef = sum(weights)
def fit(self, X: np.ndarray, y: np.ndarray, *args, **kwargs):
return self
def predict(self, X: np.ndarray):
"""Apply weights on each sample"""
return (
np.stack([np.correlate(x, self.weights, mode="valid") for x in X])
/ self.norm_coef
)
def get_params(self, deep: bool):
return {"weights": self.weights}
window_weights = np.arange(1, 25, 1) ** 2
model = RegressionModel(
lags=24,
output_chunk_length=24,
model=CustomRegressionModel(window_weights),
multi_models=False,
)
model.fit(ts_energy_train)
pred = model.predict(n=24)
ts_energy_train[-48:].plot(label="training")
ts_energy_val[:24].plot(label="validation")
pred.plot(label="forecast")
[16]:
<Axes: xlabel='Timestamp'>
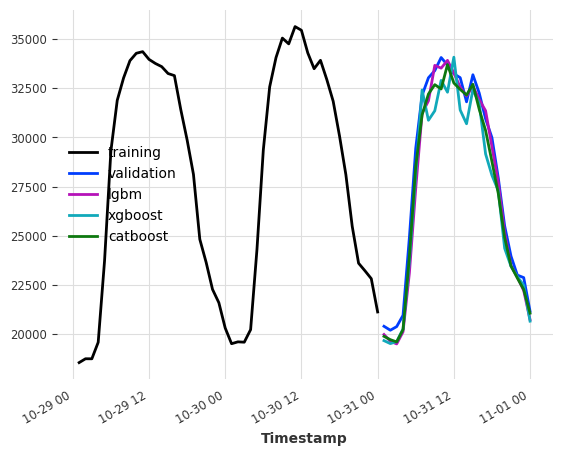
提升树模型示例¶
请确保已安装 lightgbm 和 catboost 的依赖项。您可以在此处查看我们的安装指南
[17]:
lgbm_model = LightGBMModel(lags=24, output_chunk_length=24, verbose=0)
xgboost_model = XGBModel(lags=24, output_chunk_length=24)
catboost_model = CatBoostModel(lags=24, output_chunk_length=24)
lgbm_model.fit(ts_energy_train)
xgboost_model.fit(ts_energy_train)
catboost_model.fit(ts_energy_train)
pred_lgbm = lgbm_model.predict(n=24)
pred_xgboost = xgboost_model.predict(n=24)
pred_catboost = catboost_model.predict(n=24)
print(f"LightGBMModel MAPE: {mape(ts_energy_val, pred_lgbm)}")
print(f"XGBoostModel MAPE: {mape(ts_energy_val, pred_xgboost)}")
print(f"CatboostModel MAPE: {mape(ts_energy_val, pred_catboost)}")
ts_energy_train[-48:].plot(label="training")
ts_energy_val[:24].plot(label="validation")
pred_lgbm.plot(label="lgbm")
pred_xgboost.plot(label="xgboost")
pred_catboost.plot(label="catboost")
LightGBMModel MAPE: 2.2682070257112743
XGBoostModel MAPE: 3.5364068635935895
CatboostModel MAPE: 2.373275454432286
[17]:
<Axes: xlabel='Timestamp'>