时间融合Transformer¶
在本 notebook 中,我们将展示使用 Darts 的 TFTModel 的两个示例。如果您是 darts 的新手,我们建议您先遵循快速入门 notebook。
[1]:
# fix python path if working locally
from utils import fix_pythonpath_if_working_locally
fix_pythonpath_if_working_locally()
[2]:
%load_ext autoreload
%autoreload 2
%matplotlib inline
[3]:
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from darts import TimeSeries, concatenate
from darts.dataprocessing.transformers import Scaler
from darts.datasets import AirPassengersDataset, IceCreamHeaterDataset
from darts.metrics import mape
from darts.models import TFTModel
from darts.utils.likelihood_models.torch import QuantileRegression
from darts.utils.statistics import check_seasonality, plot_acf
from darts.utils.timeseries_generation import datetime_attribute_timeseries
warnings.filterwarnings("ignore")
import logging
logging.disable(logging.CRITICAL)
时间融合Transformer (TFT)¶
Darts 的 TFTModel 包含了原始时间融合Transformer (TFT) 架构的以下主要组件,如这篇论文中所述
门控机制:跳过模型架构中未使用的组件
变量选择网络:在每个时间步选择相关的输入变量。
使用 LSTMs(长短期记忆)处理过去和未来的时间输入
多头注意力:捕获长期时间依赖性
预测区间:默认情况下,生成分位数预测而非确定性值
训练¶
TFTModel 可以使用过去和未来协变量进行训练。它在由编码器和解码器部分组成的固定大小数据块上进行顺序训练
编码器:具有
input_chunk_length的过去输入过去目标:必需
过去协变量:可选
解码器:具有
output_chunk_length的未来已知输入未来协变量:必需(如果没有可用的,请考虑
TFTModel的可选参数add_encoders或add_relative_index,详见此处)
在每次迭代中,模型在解码器部分生成形状为 (output_chunk_length, n_quantiles) 的分位数预测。
预测¶
概率预测¶
默认情况下,TFTModel 使用 QuantileRegression 生成概率分位数预测。这给出了每个预测步骤中可能目标值的范围。Darts 中的大多数深度学习模型 - 包括 TFTModel - 支持 QuantileRegression 和其他 16 种似然函数,通过在创建模型时设置 likelihood=MyLikelihood() 来生成概率预测。
为了生成有意义的结果,在预测时设置 num_samples >> 1。例如
model.predict(*args, **kwargs, num_samples=200)
预测范围为 n 的预测结果是通过使用与训练时相同大小的编码器-解码器数据块自回归生成的。
如果 n > output_chunk_length,您必须为您传递给 model.train() 的协变量提供额外的未来值。
确定性预测¶
要生成确定性预测而非概率预测,请在创建模型时将参数 likelihood 设置为 None,将 loss_fn 设置为 PyTorch 损失函数。例如
model = TFTModel(*args, **kwargs, likelihood=None, loss_fn=torch.nn.MSELoss())
...
model.predict(*args, **kwargs, num_samples=1)
[4]:
# before starting, we define some constants
num_samples = 200
figsize = (9, 6)
lowest_q, low_q, high_q, highest_q = 0.01, 0.1, 0.9, 0.99
label_q_outer = f"{int(lowest_q * 100)}-{int(highest_q * 100)}th percentiles"
label_q_inner = f"{int(low_q * 100)}-{int(high_q * 100)}th percentiles"
航空乘客示例¶
此数据集高度依赖于协变量。知道月份可以告诉我们很多关于季节性成分的信息,而年份则决定了趋势成分的影响。
此外,让我们将时间索引转换为整数值,并将其用作协变量。
这三个协变量在未来都是已知的,可以与 TFTModel 一起用作 future_covariates。
[5]:
# Read data
series = AirPassengersDataset().load()
# we convert monthly number of passengers to average daily number of passengers per month
series = series / TimeSeries.from_values(series.time_index.days_in_month)
series = series.astype(np.float32)
# Create training and validation sets:
training_cutoff = pd.Timestamp("19571201")
train, val = series.split_after(training_cutoff)
# Normalize the time series (note: we avoid fitting the transformer on the validation set)
transformer = Scaler()
train_transformed = transformer.fit_transform(train)
val_transformed = transformer.transform(val)
series_transformed = transformer.transform(series)
# create year, month and integer index covariate series
covariates = datetime_attribute_timeseries(series, attribute="year", one_hot=False)
covariates = covariates.stack(
datetime_attribute_timeseries(series, attribute="month", one_hot=False)
)
covariates = covariates.stack(
TimeSeries.from_times_and_values(
times=series.time_index,
values=np.arange(len(series)),
columns=["linear_increase"],
)
)
covariates = covariates.astype(np.float32)
# transform covariates (note: we fit the transformer on train split and can then transform the entire covariates series)
scaler_covs = Scaler()
cov_train, cov_val = covariates.split_after(training_cutoff)
scaler_covs.fit(cov_train)
covariates_transformed = scaler_covs.transform(covariates)
创建模型¶
如果您想生成确定性预测而不是分位数预测,可以使用 PyTorch 损失函数(即,设置 loss_fn=torch.nn.MSELoss() 和 likelihood=None)。
只有提供了未来的输入,才能使用 TFTModel。可选参数 add_encoders 和 add_relative_index 会很有用,尤其是在我们没有任何未来输入的情况下。它们生成用于未来协变量的编码时间数据。
由于我们在示例中已经定义了未来协变量,因此它们被注释掉了。
[6]:
# default quantiles for QuantileRegression
quantiles = [
0.01,
0.05,
0.1,
0.15,
0.2,
0.25,
0.3,
0.4,
0.5,
0.6,
0.7,
0.75,
0.8,
0.85,
0.9,
0.95,
0.99,
]
input_chunk_length = 24
forecast_horizon = 12
my_model = TFTModel(
input_chunk_length=input_chunk_length,
output_chunk_length=forecast_horizon,
hidden_size=64,
lstm_layers=1,
num_attention_heads=4,
dropout=0.1,
batch_size=16,
n_epochs=300,
add_relative_index=False,
add_encoders=None,
likelihood=QuantileRegression(
quantiles=quantiles
), # QuantileRegression is set per default
# loss_fn=MSELoss(),
random_state=42,
)
训练 TFT¶
接下来,我们可以将整个 covariates 序列作为 future_covariates 参数提供给模型;模型将对这些协变量进行切片,并仅使用训练预测目标 train_transformed 所需的部分
[7]:
my_model.fit(train_transformed, future_covariates=covariates_transformed, verbose=True)
[7]:
TFTModel(hidden_size=64, lstm_layers=1, num_attention_heads=4, full_attention=False, feed_forward=GatedResidualNetwork, dropout=0.1, hidden_continuous_size=8, categorical_embedding_sizes=None, add_relative_index=False, loss_fn=None, likelihood=<darts.utils.likelihood_models.torch.QuantileRegression object at 0x7f92e0d64c70>, norm_type=LayerNorm, use_static_covariates=True, input_chunk_length=24, output_chunk_length=12, batch_size=16, n_epochs=300, add_encoders=None, random_state=42)
查看验证集上的预测结果¶
我们使用“当前”模型(即训练过程结束时的模型)对未来 24 个月进行一次性预测
[8]:
def eval_model(model, n, actual_series, val_series):
pred_series = model.predict(n=n, num_samples=num_samples)
# plot actual series
plt.figure(figsize=figsize)
actual_series[: pred_series.end_time()].plot(label="actual")
# plot prediction with quantile ranges
pred_series.plot(
low_quantile=lowest_q, high_quantile=highest_q, label=label_q_outer
)
pred_series.plot(low_quantile=low_q, high_quantile=high_q, label=label_q_inner)
plt.title(f"MAPE: {mape(val_series, pred_series):.2f}%")
plt.legend()
eval_model(my_model, 24, series_transformed, val_transformed)
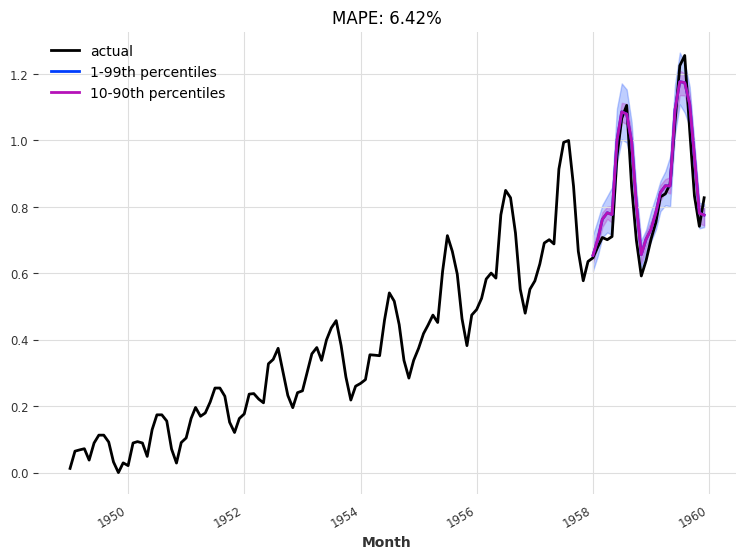
回测¶
让我们回测 TFTModel 模型,看看它在过去 3 年、预测范围为 12 个月的情况下的表现
[9]:
backtest_series = my_model.historical_forecasts(
series_transformed,
future_covariates=covariates_transformed,
start=train.end_time() + train.freq,
num_samples=num_samples,
forecast_horizon=forecast_horizon,
stride=forecast_horizon,
last_points_only=False,
retrain=False,
verbose=True,
)
[10]:
def eval_backtest(backtest_series, actual_series, horizon, start, transformer):
plt.figure(figsize=figsize)
actual_series.plot(label="actual")
backtest_series.plot(
low_quantile=lowest_q, high_quantile=highest_q, label=label_q_outer
)
backtest_series.plot(low_quantile=low_q, high_quantile=high_q, label=label_q_inner)
plt.legend()
plt.title(f"Backtest, starting {start}, {horizon}-months horizon")
print(
"MAPE: {:.2f}%".format(
mape(
transformer.inverse_transform(actual_series),
transformer.inverse_transform(backtest_series),
)
)
)
eval_backtest(
backtest_series=concatenate(backtest_series),
actual_series=series_transformed,
horizon=forecast_horizon,
start=training_cutoff,
transformer=transformer,
)
MAPE: 4.90%
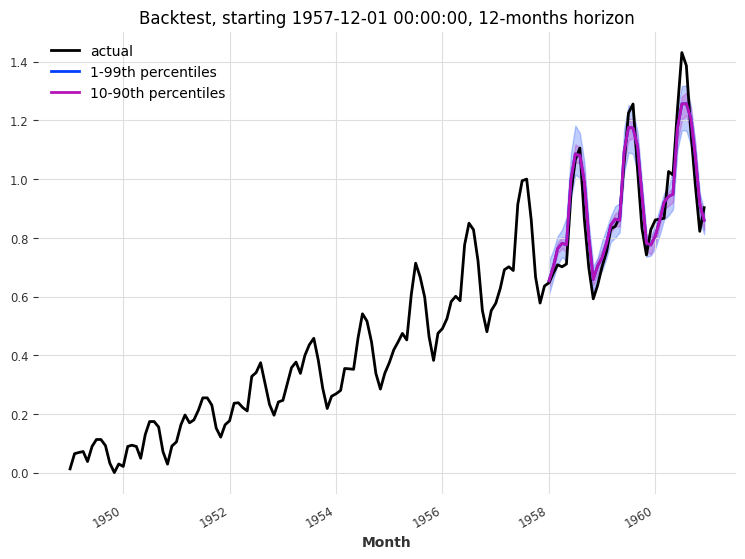
每月冰淇淋销量¶
让我们尝试另一个数据集。该数据集包含自 2004 年以来的每月冰淇淋和取暖器销量。我们的目标是预测未来的冰淇淋销量。首先,我们从数据构建时间序列,并检查其周期性。
[11]:
series_ice_heater = IceCreamHeaterDataset().load()
plt.figure(figsize=figsize)
series_ice_heater.plot()
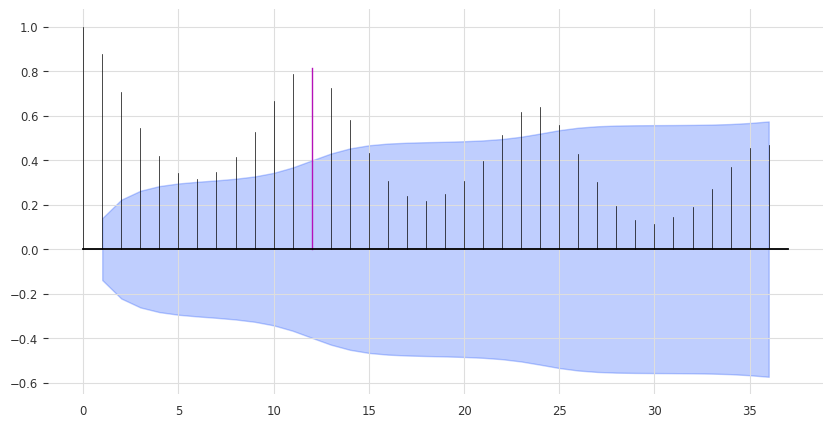
print(check_seasonality(series_ice_heater["ice cream"], max_lag=36))
print(check_seasonality(series_ice_heater["heater"], max_lag=36))
plt.figure(figsize=figsize)
plot_acf(series_ice_heater["ice cream"], 12, max_lag=36) # ~1 year seasonality
(True, 12)
(True, 12)

<Figure size 900x600 with 0 Axes>
处理数据¶
我们再次遇到了 12 个月的季节性。这次我们将不定义每月的未来协变量 -> 我们让模型自己处理!
我们来定义过去协变量。如果我们使用过去的取暖器销量数据来预测冰淇淋销量会怎样?
[12]:
# convert monthly sales to average daily sales per month
converted_series = []
for col in ["ice cream", "heater"]:
converted_series.append(
series_ice_heater[col]
/ TimeSeries.from_values(series_ice_heater.time_index.days_in_month)
)
converted_series = concatenate(converted_series, axis=1)
converted_series = converted_series[pd.Timestamp("20100101") :]
# define train/validation cutoff time
forecast_horizon_ice = 12
training_cutoff_ice = converted_series.time_index[-(2 * forecast_horizon_ice)]
# use ice cream sales as target, create train and validation sets and transform data
series_ice = converted_series["ice cream"]
train_ice, val_ice = series_ice.split_before(training_cutoff_ice)
transformer_ice = Scaler()
train_ice_transformed = transformer_ice.fit_transform(train_ice)
val_ice_transformed = transformer_ice.transform(val_ice)
series_ice_transformed = transformer_ice.transform(series_ice)
# use heater sales as past covariates and transform data
covariates_heat = converted_series["heater"]
cov_heat_train, cov_heat_val = covariates_heat.split_before(training_cutoff_ice)
transformer_heat = Scaler()
transformer_heat.fit(cov_heat_train)
covariates_heat_transformed = transformer_heat.transform(covariates_heat)
创建自动生成未来协变量并训练的模型¶
由于我们没有定义未来协变量,我们需要告诉模型自己生成未来协变量。
add_encoders:可以从日期时间属性、周期性重复时间模式、索引位置以及用于索引编码的自定义函数中添加多个编码作为过去和/或未来协变量。您甚至可以添加一个处理训练、验证和预测数据适当缩放的转换器!有关更多信息,请参阅TFTModel文档,详见此处add_relative_index:为每个编码器-解码器数据块添加相对于预测点的缩放整数位置(如果您确实不想使用任何未来协变量,这可能会很有用。位置值在所有数据块中保持恒定,不添加额外信息)。
我们使用 add_encoders={'cyclic': {'future': ['month']}} 将 12 个月的季节性作为未来协变量来考虑..
[13]:
# use the last 3 years as past input data
input_chunk_length_ice = 36
# use `add_encoders` as we don't have future covariates
my_model_ice = TFTModel(
input_chunk_length=input_chunk_length_ice,
output_chunk_length=forecast_horizon_ice,
hidden_size=32,
lstm_layers=1,
batch_size=16,
n_epochs=300,
dropout=0.1,
add_encoders={"cyclic": {"future": ["month"]}},
add_relative_index=False,
optimizer_kwargs={"lr": 1e-3},
random_state=42,
)
# fit the model with past covariates
my_model_ice.fit(
train_ice_transformed, past_covariates=covariates_heat_transformed, verbose=True
)
[13]:
TFTModel(hidden_size=32, lstm_layers=1, num_attention_heads=4, full_attention=False, feed_forward=GatedResidualNetwork, dropout=0.1, hidden_continuous_size=8, categorical_embedding_sizes=None, add_relative_index=False, loss_fn=None, likelihood=None, norm_type=LayerNorm, use_static_covariates=True, input_chunk_length=36, output_chunk_length=12, batch_size=16, n_epochs=300, add_encoders={'cyclic': {'future': ['month']}}, optimizer_kwargs={'lr': 0.001}, random_state=42)
查看验证集上的预测结果¶
同样,我们使用“当前”模型(即训练过程结束时的模型)对未来 24 个月进行一次性预测
[14]:
n = 24
eval_model(
model=my_model_ice,
n=n,
actual_series=series_ice_transformed[
train_ice.end_time() - (2 * n - 1) * train_ice.freq :
],
val_series=val_ice_transformed,
)
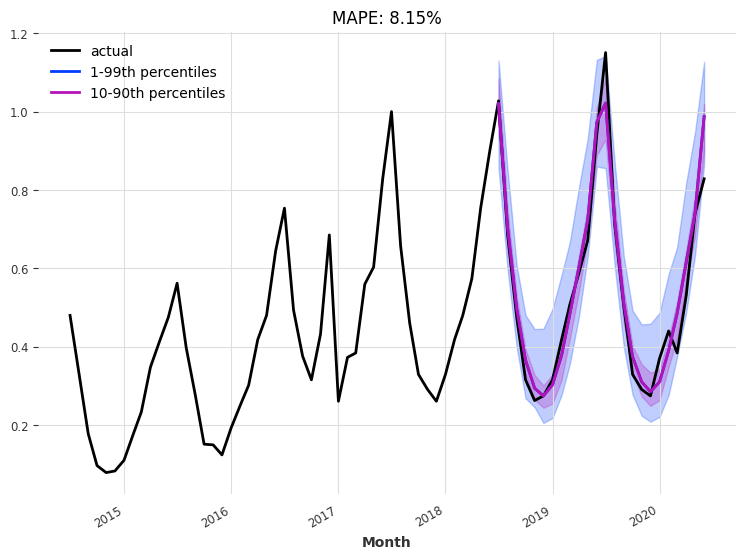
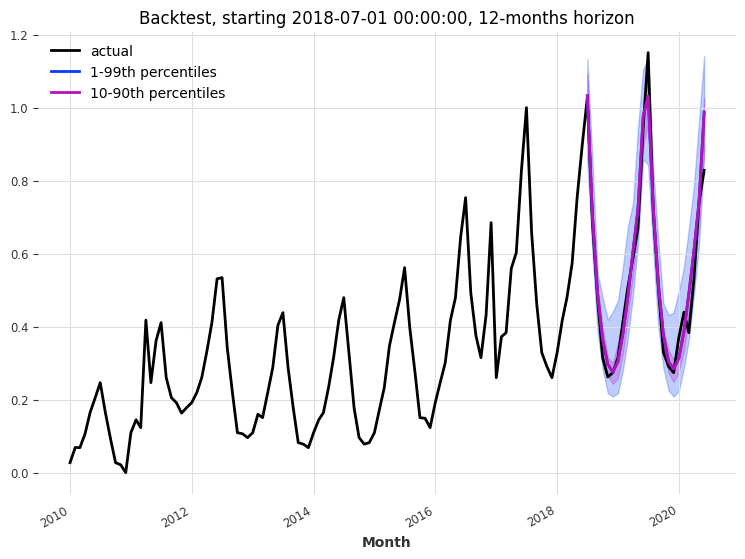
回测¶
让我们回测 TFTModel 模型,看看它在过去 2 年、预测范围为 12 个月的情况下的表现
[15]:
# Compute the backtest predictions with the two models
last_points_only = False
backtest_series_ice = my_model_ice.historical_forecasts(
series_ice_transformed,
num_samples=num_samples,
start=training_cutoff_ice,
forecast_horizon=forecast_horizon_ice,
stride=1 if last_points_only else forecast_horizon_ice,
retrain=False,
last_points_only=last_points_only,
overlap_end=True,
verbose=True,
)
backtest_series_ice = (
concatenate(backtest_series_ice)
if isinstance(backtest_series_ice, list)
else backtest_series_ice
)
[16]:
eval_backtest(
backtest_series=backtest_series_ice,
actual_series=series_ice_transformed[
train_ice.start_time() - 2 * forecast_horizon_ice * train_ice.freq :
],
horizon=forecast_horizon_ice,
start=training_cutoff_ice,
transformer=transformer_ice,
)
MAPE: 5.32%
可解释性¶
让我们试着理解 TFTModel 模型学到了什么。了解特征重要性以及模型对过去和未来输入的关注程度会很有帮助。
TFTExplainer 正是为此而设计的!您可以在此处找到文档。
[17]:
from darts.explainability import TFTExplainer
要实例化解释器,我们有两种选择:- 传递自定义背景序列输入,用作解释的默认输入。- 让解释器自动从模型加载背景。这仅在模型在单个目标序列上进行训练时才可能(如我们的情况)。
[18]:
explainer = TFTExplainer(my_model_ice)
现在我们可以使用 explain() 生成解释。同样,我们有两种选择:- 传递自定义前景序列输入进行解释 - 不传递任何前景来解释背景
[19]:
explainability_result = explainer.explain()
让我们看看特征重要性:- 编码器特征重要性:包含过去目标、过去协变量和“历史”未来协变量(输入数据块中未来协变量的值)- 解码器特征重要性:包含“未来”未来协变量(输出数据块中未来协变量的值)- 静态协变量重要性:静态变量的重要性(仅当模型在包含静态协变量的 series 上训练时显示)
[20]:
explainer.plot_variable_selection(explainability_result)
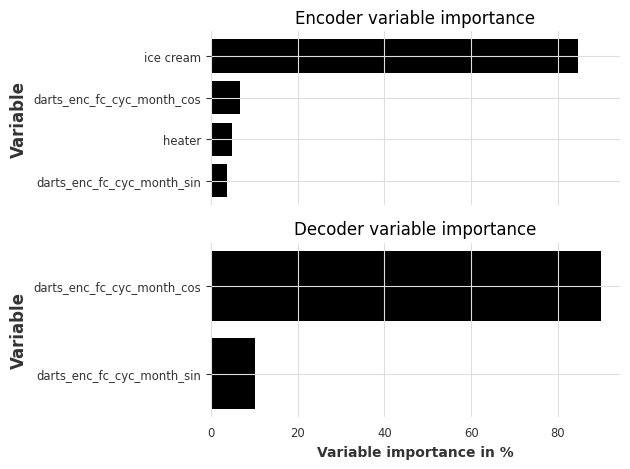
正如预期的那样,冰淇淋销量的过去历史是编码器中最重要的特征。月份的周期性编码也有助于编码器和解码器学习季节性模式。
让我们看看模型对过去和未来输入的关注度(权重)。
我们有多种绘图选项
plot_type - “time” - 绘制在所有预测步骤上聚合的注意力 - “all” - 单独绘制每个预测步骤的注意力(范围从 1 到 output_chunk_length)- “heatmap” - 将每个预测步骤的所有注意力绘制为热力图
show_index_as - “relative” - 将 x 轴设置为相对于第一个预测时间步,范围从 -input_chunk_length 到 output_chunk_length - 1。0 表示第一个预测时间步(由虚线突出显示)。- “time” - 使用 x 轴上的实际时间索引。虚线突出显示第一个预测时间步。
[21]:
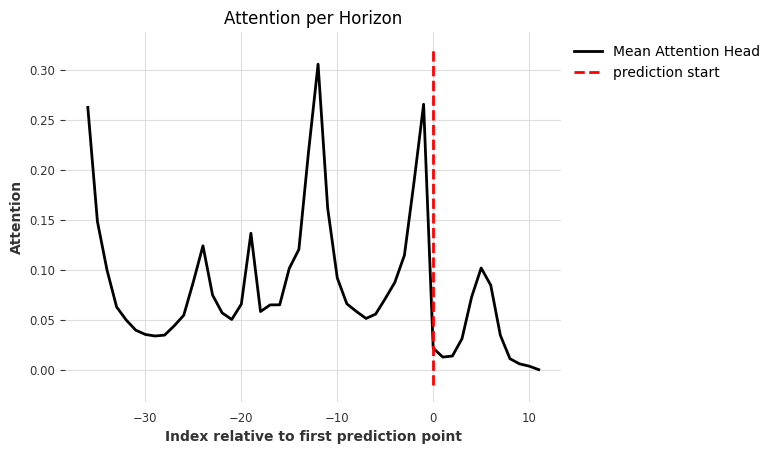
explainer.plot_attention(explainability_result, plot_type="time")
[21]:
<Axes: title={'center': 'Attention per Horizon'}, xlabel='Index relative to first prediction point', ylabel='Attention'>
我们可以看到有趣的注意力区域:- 相对索引 -12 处最大注意力。这表明存在年季节性,这对于冰淇淋销量来说是合理的。- 输入数据块的开始 (-36) 处注意力很高:这可能来自捕获当前输入的数值范围和季节性(-3 年)- 输入数据块末尾 (-1) 处注意力较高:模型关注近期过去 - 对未来输入的关注(我们将在下一个图中进一步查看)
[22]:
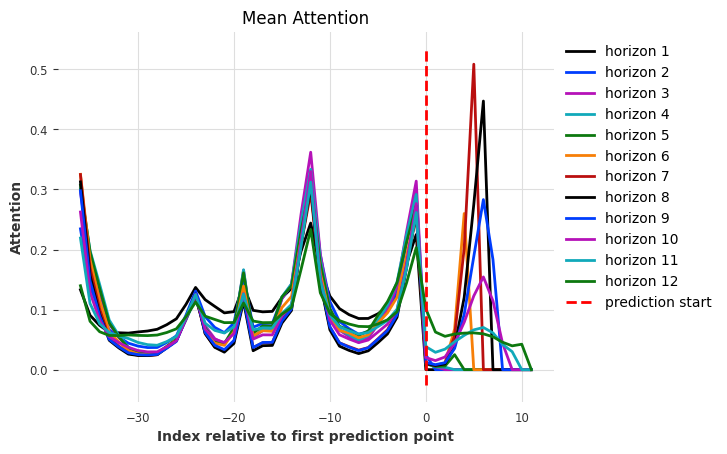
explainer.plot_attention(explainability_result, plot_type="all")
[22]:
<Axes: title={'center': 'Mean Attention'}, xlabel='Index relative to first prediction point', ylabel='Attention'>
在输出数据块(索引 0 - 11)上,我们看到模型只关注每个预测范围的过去相对值。这是因为 TFTModel 默认使用 full_attention=False。当将其设置为 True 时,模型也将关注当前和未来输入。
[23]:
explainer.plot_attention(explainability_result, plot_type="heatmap")
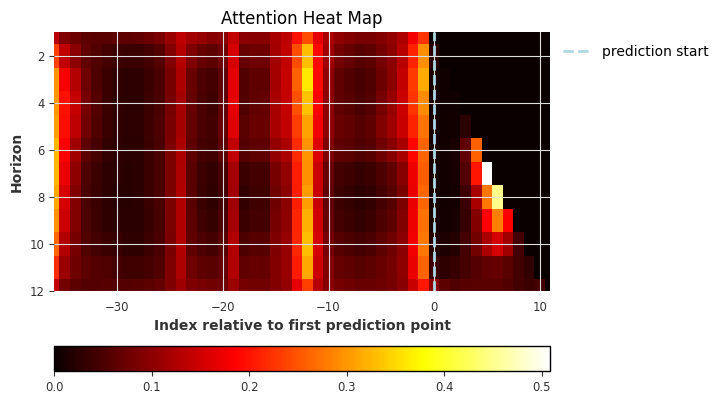
[23]:
<Axes: title={'center': 'Attention Heat Map'}, xlabel='Index relative to first prediction point', ylabel='Horizon'>
我们还可以直接从 exlainability_result 中获取值。您可以在此处找到文档。
[24]:
explainability_result.get_encoder_importance()
[24]:
| darts_enc_fc_cyc_month_sin | heater | darts_enc_fc_cyc_month_cos | ice cream | |
|---|---|---|---|---|
| 0 | 3.7 | 4.8 | 6.8 | 84.7 |
[25]:
explainability_result.get_decoder_importance()
[25]:
| darts_enc_fc_cyc_month_sin | darts_enc_fc_cyc_month_cos | |
|---|---|---|
| 0 | 10.2 | 89.8 |
[26]:
explainability_result.get_static_covariates_importance()
[26]:
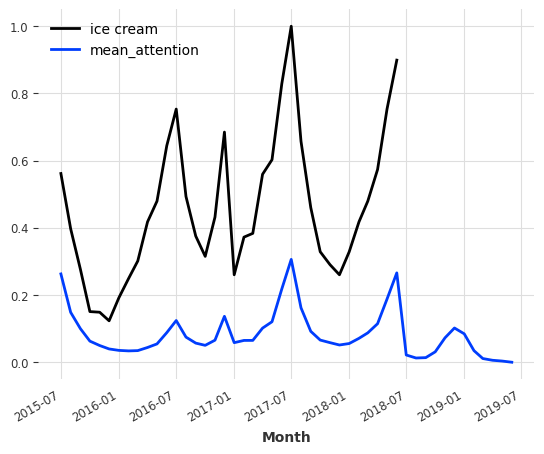
我们还可以将注意力提取为时间序列,并对照数据进行绘制。
[27]:
attention = explainability_result.get_attention().mean(axis=1)
time_intersection = train_ice_transformed.time_index.intersection(attention.time_index)
train_ice_transformed[time_intersection].plot()
attention.plot(label="mean_attention", max_nr_components=12)
更多信息¶
虽然我们只看了一个单变量预测示例,但 TFTExplainer 可以无缝应用于多变量和/或多个 TimeSeries 的用例。